
本期内容:
1,Spark Streaming数据清理原因和现象
2,Spark Streaming数据清理代码解析
因为RDD是由DStream产生的,对RDD的操作都是基于对DStream的操作,DStream负责RDD的生命周期。我们一般会调用DStream的foreachRDD操作,进行输出到HDFS的操作。foreachRDD操作会实例化ForEachDStream对象。
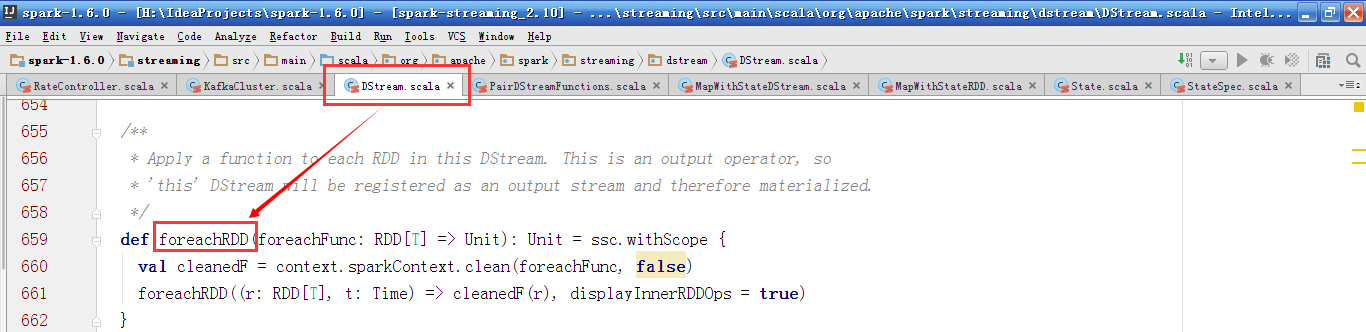

在ForEachDStream的generateJob方法中,调用了传入的方法foreachFunc,作用在这个BatchTime生成的RDD。

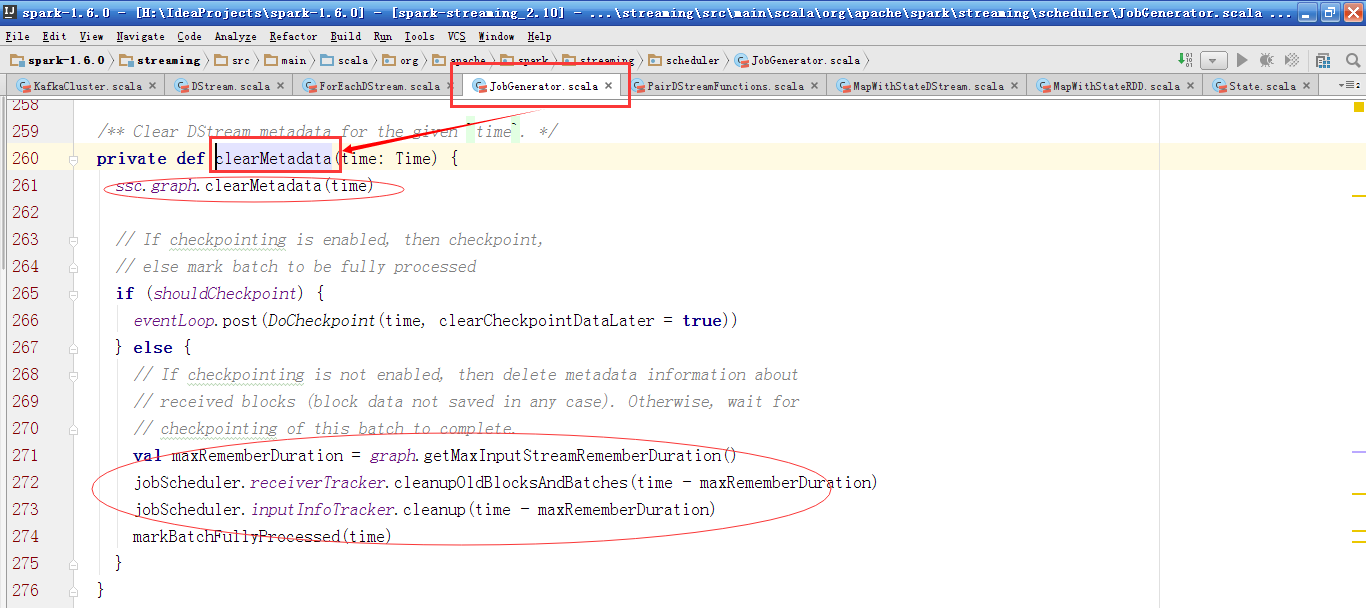
在JobGenerator类中处理消息的函数processEvent中,当接收到清除元数据消息,则调用clearMetadata方法,当接收到清除checkpoint数据,则调用clearCheckpointData方法。

clearMetadata方法中,先清除DStreamGraph的metadata信息,然后根据是否进行checkpoin操作,或是发送DoCheckpoint消息,或是清除掉ReceiverTracker和InputInfoTracker上之前的数据。
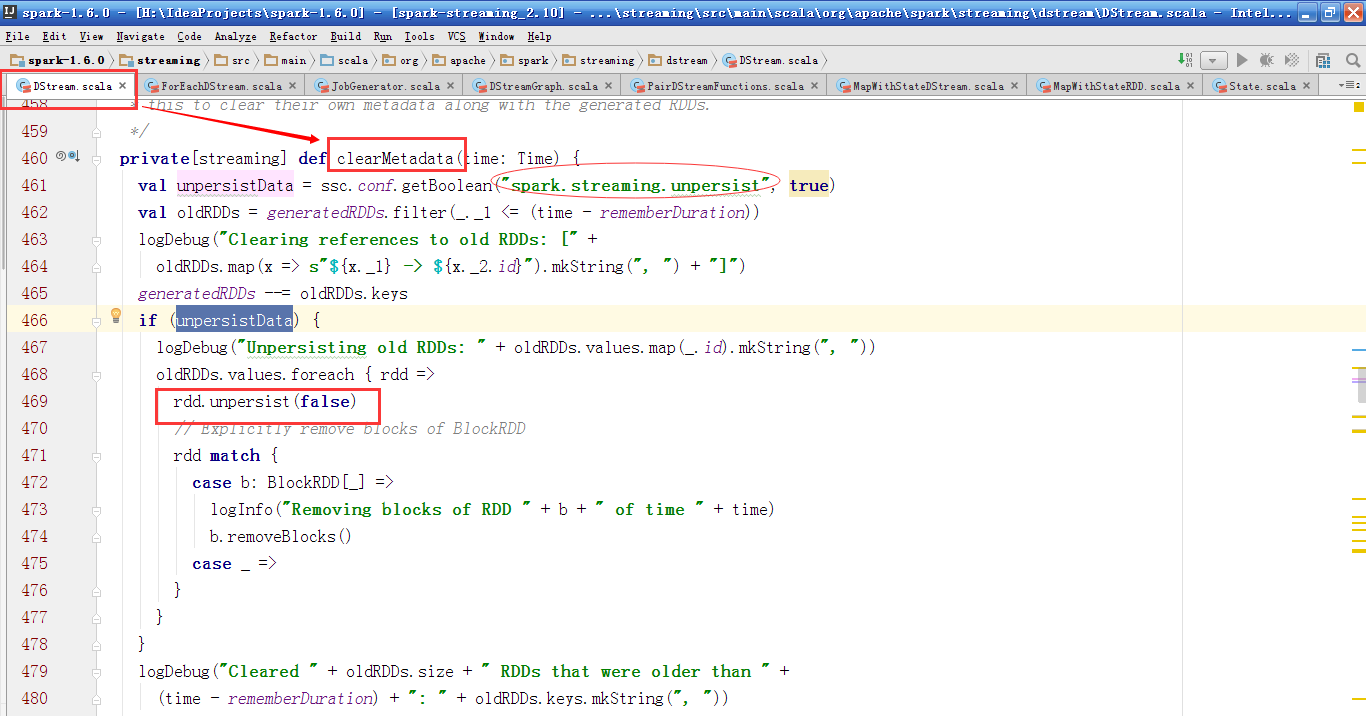
DStreamGraph的clearMetadata方法会遍历并调用所有OutputStream的clearMetadata方法,把之前persist的RDD进行unpersist操作,从generatedRDDs中清除掉,如果是BlockRDD的话,还会调用removeBlocks方法来移除,最后删除它的依赖dependencies.foreach(_.clearMetadata(time))。
当前Batch完成后会发送ClearMetadata消息。
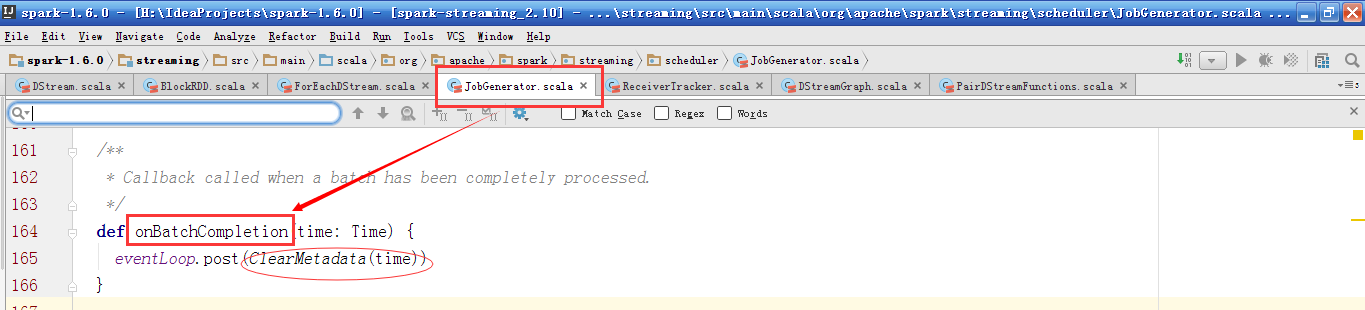
onBatchCompletion方法是被handleJobComplation方法调用的。
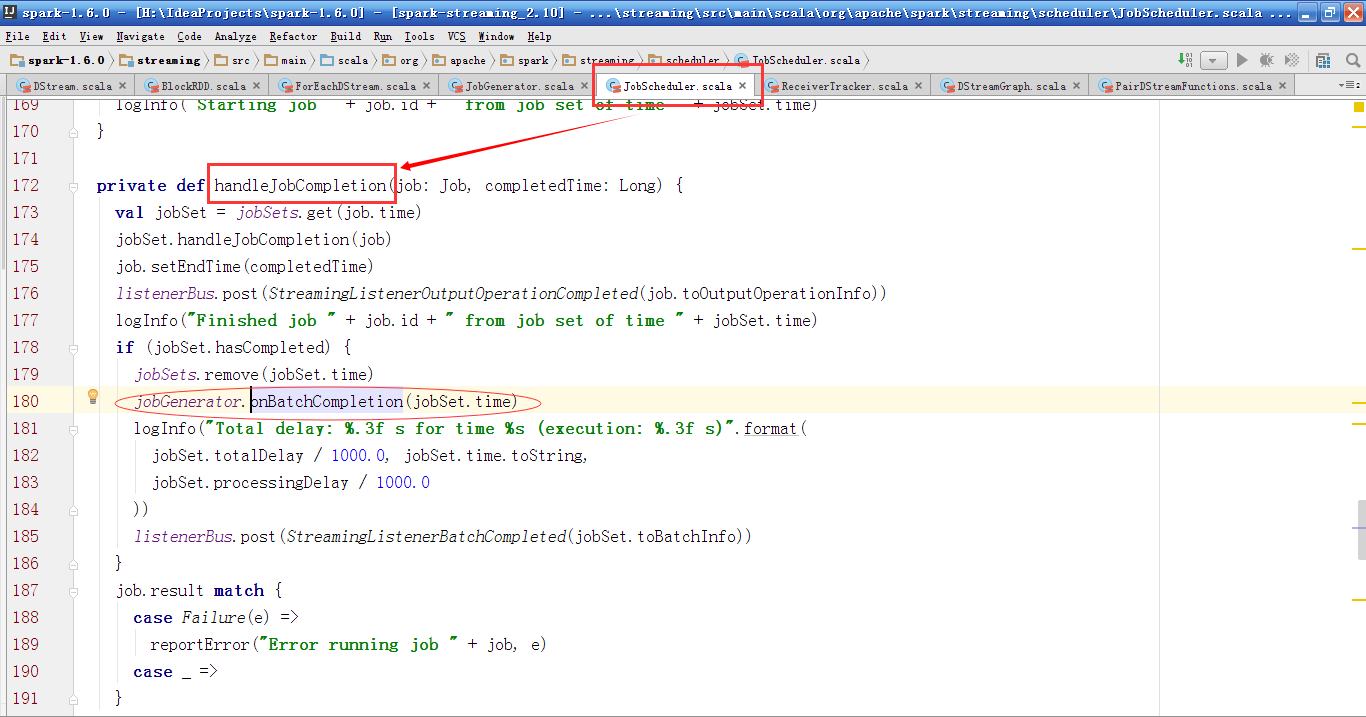
handleJobComplation方法是接收到JobCompleted消息时调用的。

在JobHandler的执行过程中,先会发送JobStarted消息,然后调用job的run方法,最后发送JobCompleted消息。
